
Building a Text Similarity checker with Hugging face and Streamlit

Hey there, I'm Joas, I am a self-taught data analyst and AI engineer in the making. With a passion for technology and a keen interest in the field of artificial intelligence, I have been honing my skills through various online resources and self-guided projects. My goal is to use my expertise to contribute to the development of innovative solutions that will make a positive impact on society.
Introduction
Hugging Face is a widely used platform for creating, sharing, and deploying Natural Language Processing (NLP) models. Its transformers library includes pre-trained models such as Bert, and GPT-3, which can be fine-tuned for a variety of NLP tasks including text similarity checking, making it a popular solution for developers worldwide. In this article, we will delve into how to build a text similarity checker using Hugging Face's pre-trained models and Streamlit, a robust Python framework for creating interactive web applications.
Prerequisites
Before we start building our text similarity checker, there are a few things you need to have in place:
Basic knowledge of Python programming language
Understanding of NLP concepts and techniques
Familiarity with Hugging Face Transformers library
Installation of Python packages such as Streamlit
If you are new to any of these concepts it might be a good idea to do some background reading or take an introductory course on them. But we'll make it easier for everyone to follow along.
Now let's dive in
We will be using the sentence-transformers/all-MiniLM-L6-v2 for our text similarity checker.This model is a type of sentence-transformers model, which is capable of mapping sentences and paragraphs to a 384-dimensional vector space. This makes it an ideal choice for tasks such as clustering or semantic search.
Step 1: Building the similarity checker: code breakdown
First, we need to import the 'SentenceTransformers' class from the 'sentence_transformers' package and the 'torch' library. we will then create an instance of the 'SentenceTransformers' class and load our pre-trained model 'sentence-transformers/all-MiniLM-L6-v2'.
from sentence_transformers import SentenceTransformer
import torch
# Load model
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
Then we define two sentences that we will use to compute the similarity score
# Define two example sentences
sentence1 = "The quick brown fox jumps over the lazy dog"
sentence2 = "A quick brown dog jumps over the lazy fox"
After that, we encode the two sentences into 384-dimensional dense vectors using the pre-trained model. We then compute the cosine similarity between the two vectors using the 'cosine_similarity' function from the 'torch.nn.fucntional' module
# Encode sentences and compute similarity score
embeddings1 = model.encode([sentence1], convert_to_tensor=True)
embeddings2 = model.encode([sentence2], convert_to_tensor=True)
cosine_similarities = torch.nn.functional.cosine_similarity(embeddings1, embeddings2)
Finally, we print the similarity score between the two sentences
# Print similarity score
print(f"Similarity score: {cosine_similarities.item()}")
Step 2: Building the Streamlit app
First, let's import the necessary libraries and load the pre-trained model. We are using 'Streamlit' to build the app and 'sentence_transformer' library to perform the similarity calculations.
# Import necessary libraries
import streamlit as st
from sentence_transformers import SentenceTransformer
import torch
# Load the pre-trained sentence-transformers model
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
Then, we define a function to compute similarity scores using the pre-trained model. This function takes in a source sentence and a list of sentences to compare with, encodes the sentences using the pre-trained model, computes the cosine similarity scores, and returns the similarity scores as a list.
# Define a function to compute similarity scores
def compute_similarity_score(source_sentence, compare_sentences):
# Encode the source sentence
source_embedding = model.encode(source_sentence, convert_to_tensor=True)
# Encode the compare sentences
compare_embeddings = model.encode(compare_sentences, convert_to_tensor=True)
# Compute cosine similarity scores
cosine_similarities = torch.nn.functional.cosine_similarity(source_embedding, compare_embeddings)
# Return the similarity scores
return cosine_similarities.tolist()
Next, we can set the page configuration, sidebar, and input fields using 'streamlit'. We are setting the title of the app, the page icon, and the layout. In the sidebar, we are adding input fields for the source sentence and up to three sentences to compare with.
# Set page configuration
st.set_page_config(page_title="Sentence Similarity Score", page_icon=":guardsman:", layout="wide")
# Set sidebar
st.sidebar.title("Sentence Similarity Score")
# Add input fields to the sidebar
with st.sidebar:
source_sentence = st.text_input(label="Enter the source sentence:")
compare_sentences = []
for i in range(3):
compare_sentence = st.text_input(label=f"Enter sentence {i+1} to compare (optional):", key=f"compare_sentence_{i}")
if compare_sentence:
compare_sentences.append(compare_sentence)
Finally, we compute the similarity scores when the "Compute Similarity Scores" button is clicked. We check if a source sentence is entered, and if so, compute the similarity scores using the 'compute_similarity_score()' function. We then display the results in two columns using 'streamlit'. The first column displays the score for each sentence, and the second column displays the corresponding sentence.
# Compute similarity scores
if st.button("Compute Similarity Scores"):
if not source_sentence:
st.error("Please enter a source sentence.")
else:
scores = compute_similarity_score(source_sentence, compare_sentences)
# Display results
col1, col2 = st.beta_columns([1, 2])
with col1:
st.write("Score")
st.write("---")
for i, score in enumerate(scores):
st.write(f"{i+1}. {score:.2f}")
with col2:
st.write("Sentence")
st.write("---")
st.write("Source Sentence")
for i, compare_sentence in enumerate(compare_sentences):
st.write(f"Compare Sentence {i+1}")
# Add line bar to the page
st.markdown(
"""<style>
.css-hi6a2p{border-bottom: 2px solid #6EB3D0;}
</style>""",
unsafe_allow_html=True,
)
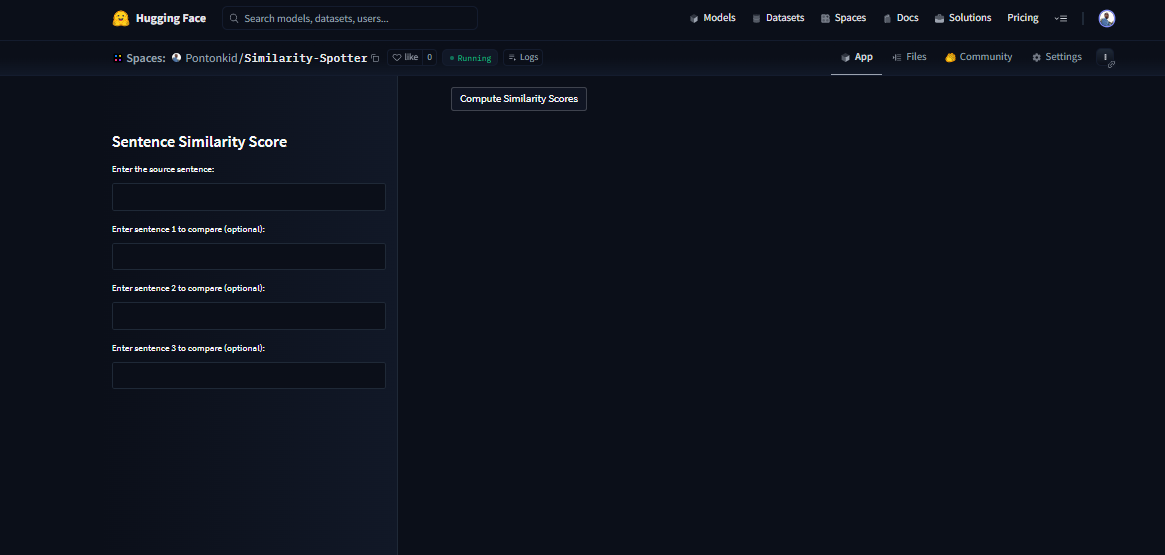
Below is a screenshot of the Streamlit app that we built for the similarity checker
Next?
Congratulations!!! You have successfully built a sentence similarity checker using the Sentence Transformers library and Streamlit. With this application, you can easily compare the similarity scores of a source sentence to a list of other sentences. Now that you have a solid foundation, the possibilities for further development are endless. For instance, you could consider integrating the similarity checker into a larger NLP pipeline, implementing more advanced similarity metrics, or even deploying the application to a web server for broader accessibility. Whatever your next step may be, I hope that this tutorial has been a helpful starting point in your journey toward building robust and scalable NLP applications.



